
- NEVISA
- 0 نظر
- 1036 بازدید
یادگیری ماشین (Machine Learning-ML) شاخهای از هوش مصنوعی (AI) و علوم کامپیوتر است که بر استفاده از دادهها و الگوریتمها تمرکز دارد. این علم به هوش مصنوعی امکان میدهد تا روشهای یادگیری انسانها را تقلید کرده و به مرور زمان دقت خود را بهبود بخشد.
به بیان سادهتر، یادگیری ماشین به کامپیوترها اجازه میدهد تا از دادههای ورودی خود بیاموزند و بدون نیاز به برنامهریزی مستقیم از سوی توسعهدهندگان، تصمیمگیری یا پیشبینی انجام دهند.
یادگیری تقویتی چیست؟
یادگیری تقویتی یکی از روشهای مهم برای آموزش سیستمهای یادگیری ماشینی است. این روش به یک عامل -چه در قالب یک شخصیت در بازی ویدیویی باشد و چه رباتی در محیط صنعتی- قدرت میدهد تا با محیط پیچیدهای که در آن قرار دارد تعامل کند و تصمیمات درستی بگیرد. با گذشت زمان، از طریق سیستمی مبتنی بر بازخورد شامل پاداش و مجازات، عامل از محیط خود یاد میگیرد و رفتارهای خود را بهینهسازی میکند. فرآیند یادگیری عامل با استفاده از پاداش و مجازات برای دستیابی به بهترین نتایج ممکن ادامه مییابد.
یادگیری تقویتی چگونه کار میکند؟
مکانیسم آموزشی یادگیری تقویتی مشابه بسیاری از سناریوهای دنیای واقعی است. به عنوان مثال، آموزش حیوانات خانگی با استفاده از پاداش را در نظر بگیرید.
مثال: نحوه کار یادگیری تقویتی
بیایید به یک نمونه خاص بپردازیم.
هدف در این مثال آموزش یک سگ (عامل) برای انجام یک کار در محیط است که شامل محیط اطراف سگ و مربی میشود. ابتدا مربی دستوری صادر میکند که سگ آن را مشاهده میکند (Observation یا مشاهده). سپس سگ با انجام یک اقدام به دستور مربی پاسخ میدهد. اگر عمل انجام شده به رفتار مورد انتظار نزدیک باشد، مربی احتمالاً به سگ پاداشی مانند غذا یا اسباببازی میدهد. در غیر این صورت، سگ پاداشی دریافت نمیکند.
در ابتدای آموزش، سگ ممکن است اقدامات اشتباهی مانند غلت زدن به جای نشستن در هنگام صدور فرمان “بنشین” انجام دهد؛ زیرا سعی دارد مشاهدات خاص را با اقدامات و پاداشها مرتبط کند. این ارتباط بین مشاهدات و اقدامات به عنوان خطمشی (Policy) شناخته میشود. از دیدگاه سگ، حالت ایدهآل این است که به هر نشانهای به درستی پاسخ دهد تا بتواند حداکثر پاداش ممکن را دریافت کند. بنابراین، هدف اصلی یادگیری تقویتی این است که ذهن سگ را به گونهای تربیت کنیم که رفتارهای مطلوب را یاد بگیرد و پاداشهای بیشتری دریافت کند. پس از اتمام آموزش، سگ باید قادر باشد با مشاهده صاحبش، اقدامات صحیح را انجام دهد. به عنوان مثال، با توجه به آموزشهای گذشته و درک فعلیاش، زمانی که دستور “نشستن” داده میشود، بنشیند و با اجرای صحیح دستور، پاداش دریافت کند.

مثال دوم نحوه کار یادگیری تقویتی
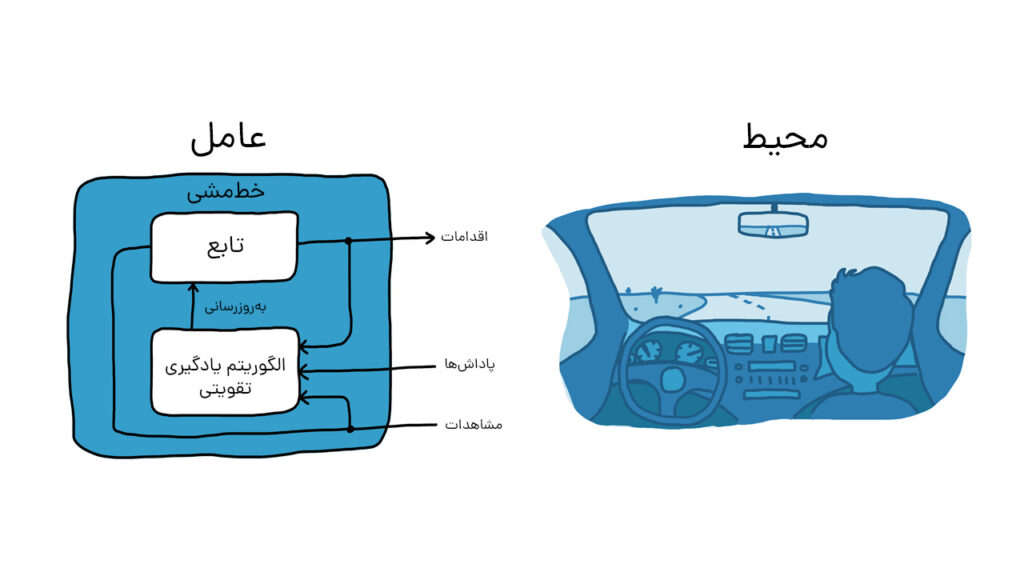
با در نظر گرفتن مثال آموزش سگ، وظیفه پارک وسیله نقلیه با استفاده از سیستم رانندگی خودکار را پیش میبریم (شکل زیر).
هدف این است که کامپیوتر (عامل) خودرو را با استفاده از یادگیری تقویتی بهطور صحیح در محل پارک کند. در مثال آموزش سگ، آنچه خارج از عامل قرار دارد، محیط نامیده میشود. در این مثال نیز، محیط میتواند شامل حرکت خودرو در خیابان، حرکت سایر وسایل نقلیه در نزدیکی، شرایط آب و هوایی و غیره باشد. در طول تمرین، عامل از دادههایی که توسط حسگرهایی نظیر دوربینها، جیپیاس و لیدار بهعنوان مشاهدات دریافت میشود، برای تولید فرمانهایی مانند ترمز و شتاب (عملکرد) استفاده میکند. برای یادگیری نحوه انجام اقدامات صحیح در مقابل مشاهدات (تنظیم خطمشی یا Policy)، کامپیوتر بارها سعی میکند وسیله نقلیه را با استفاده از فرآیند آزمون و خطا پارک کند. پس از انجام اقدام صحیح توسط عامل، یک سیگنال پاداش ارسال میشود تا نشان دهد که عمل بهدرستی انجام شده و فرآیند یادگیری باید ادامه یابد.
جمعبندی مثالها
در مثال آموزش سگ، یادگیری در مغز این حیوان اتفاق میافتد. در مثال پارک خودکار، آموزش توسط یک الگوریتم آموزشی مدیریت میشود. الگوریتم آموزشی مسئول تنظیم خطمشی عامل بر اساس دادههای دریافتی، اقدامات و پاداشهای جمعآوریشده است. پس از اتمام آموزش، کامپیوتر خودرو باید تنها با استفاده از خطمشی تنظیمشده و پردازش اطلاعات دریافتی از حسگرها بتواند پارک کند.
نکتهای که باید در نظر داشت
یادگیری تقویتی بهطور کلی نمونهای کارآمد نیست؛ یعنی برای یادگیری و جمعآوری دادهها نیاز به تعداد زیادی تعامل بین عامل و محیط دارد. بهعنوان مثال، AlphaGo، اولین برنامه کامپیوتری که توانست یک قهرمان جهانی در بازی Go را شکست دهد، بدون وقفه برای چند روز با انجام میلیونها بازی آموزش دید و هزاران سال دانش بشری را در حافظه خود ذخیره کرد. حتی برای برنامههای نسبتاً ساده، زمان آموزش میتواند از چند دقیقه تا ساعتها یا روزها طول بکشد. همچنین شبیهسازی یک مشکل بهطور صحیح میتواند چالشبرانگیز باشد؛ زیرا فهرستی از مشکلات وجود دارد که باید طراحی شوند و برای یافتن راهحل مناسب ممکن است عامل به چندین بار تکرار عمل نیاز داشته باشد.





{kind=link}